About
Are you curious what your text is actually saying?
The current popular way of analyzing large amounts of unstructured text is with a Large Language Model (LLM). Unfortunately, it will only look for things you prompt for, cost a ton, and hallucinate.
Sparse Autoencoders (SAEs) are models trained to interpret activations (intermediate LLM calculations). Typically they're used to explain model weights, but we use them to process text via a reader model. It's like instead of asking your friend Claude to verbally tell you what he saw (which is expensive and slow and might be lies), you cut his brain open and see which neurons light up at each token position (which is two orders of magnitude cheaper). Maximal efficiency. Here's a helpful diagram.
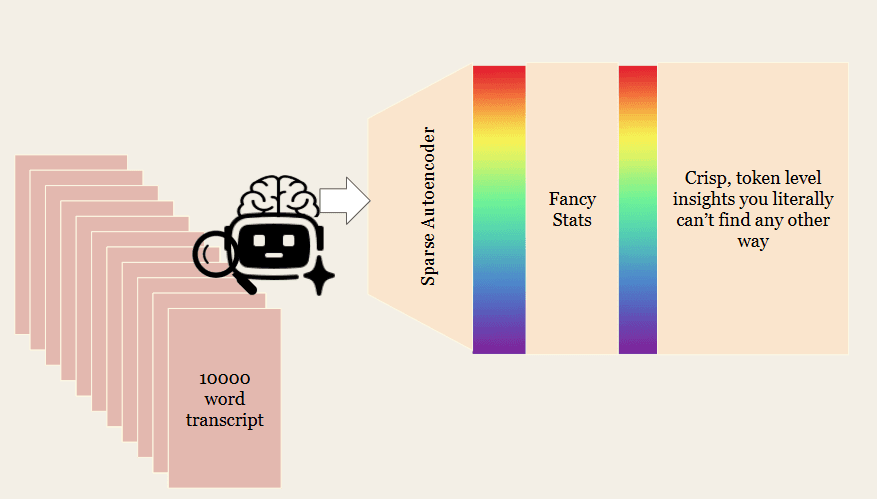
Tweets are fun, but what else can you do? You can monitor agents, optimize prompts, and even catch reward hacking in 114GB of reinforcement learning training logs.